3.18A Informatics Forum
10 Crichton Street Newington
Edinburgh EH8 9AB, UK
More details 👉here👈. Reach out for me if you want to chat about doing research in Edinburgh!
research
I am looking at
Lots of opportunities, as we are quite far from delivering
I do have a PhD in Computer Science, but I still struggle with basic English. And with all the current hype in the field.
- advancing probabilistic inference
by tracing the boundaries of tractable inference[#trac] , coping with structured and heterogeneous data[#het] , enabling complex reasoning (e.g., logical constraints)[#log] , combining it with deep models and learning[#dl] - automating probabilistic modeling
by learning everything, from model structures[#sl] to statistical data types[#typ] and learning to query[#lql] - demistifying ML
by disentangling rigorous empirical science from hype via reproducibility studies[#rep] and more love for simple baselines such as randomized approaches[#rnd]
publications
Or my DBLP, Semantic scholar and Google scholar pages.
- 2021
-
NeurIPS 2021
A Compositional Atlas of Tractable Circuit Operations for Probabilistic InferenceA systematic way to trace the tractability of complex queries by decomposing them into atomic operators over circuit representations.[ pdf | bibtex | abstract | supplemental ]Circuit representations are becoming the lingua franca to express and reason about tractable generative and discriminative models. In this paper, we show how complex inference scenarios for these models that commonly arise in machine learning---from computing the expectations of decision tree ensembles to information-theoretic divergences of sum-product networks---can be represented in terms of tractable modular operations over circuits. Specifically, we characterize the tractability of simple transformations---sums, products, quotients, powers, logarithms, and exponentials---in terms of sufficient structural constraints of the circuits they operate on, and present novel hardness results for the cases in which these properties are not satisfied. Building on these operations, we derive a unified framework for reasoning about tractable models that generalizes several results in the literature and opens up novel tractable inference scenarios.@article{vergari2021compositional, title={A Compositional Atlas of Tractable Circuit Operations for Probabilistic Inference}, author={Vergari, Antonio and Choi, YooJung and Liu, Anji and Teso, Stefano and Van den Broeck, Guy}, journal={Advances in Neural Information Processing Systems}, volume={34}, year={2021}} -
AKBC 2021
Neural Concept Formation in Knowledge GraphsLearning new entity concepts in knowledge graphs can be done by clustering entities, reifying concept memberships and augmenting the knowledge graph. This improves the generalization of neural link predictors, especially in the presence of rare predicates.[ pdf | bibtex | abstract ]We investigate how to learn novel concepts in Knowledge Graphs (KGs) in aprincipled way, and how to effectively exploit them to produce more accurateneural link prediction models. Specifically, we show how concept membershiprelationships learned via unsupervised clustering of entities can be reified andeffectively used to augment a KG. In our experiments we show that neural linkpredictors trained on these augmented KGs, or in a joint Expectation-Maximizationiterative scheme, can generalize better and produce more accurate predictions forinfrequent relationships while delivering meaningful concept representations@inproceedings{dobrowolska2021neural, title={Neural Concept Formation in Knowledge Graphs}, author={Dobrowolska, Agnieszka and Minervini, Pasquale and others}, booktitle={3rd Conference on Automated Knowledge Base Construction},year={2021}} -
TPM 2021
Exact and Efficient Adversarial Robustness with Decomposable Neural NetworksWe introduce Deconets a new type of deep neural network for which adversarial robustness can be certified exactly and efficiently via classifier smoothing.[ pdf | bibtex | abstract ]As deep neural networks are notoriously vulnerable to adversarial attacks, there has been significant interest in defenses with provable guarantees. Recent solutions advocate for a randomized smoothing approach to provide probabilistic guarantees, by estimating the expectation of a network's output when the input is randomly perturbed. As the convergence of the estimated expectations depends on the number of Monte Carlo samples, and hence network evaluations, these techniques come at the price of considerable additional computation at inference time. We take a different route and introduce a novel class of deep models---decomposable neural networks (DecoNets)---which compute the required expectation exactly and efficiently using a single network evaluation. This remarkable feature of DecoNets stems from their network structure, implementing a hierarchy of decomposable multiplicative interactions over non-linear input features, which allows to reduce the overall expectation into many "small" expectations over input units, thus delivering exact guarantees.@inproceedings{subramani2021exact, title={Exact and Efficient Adversarial Robustness with Decomposable Neural Networks}, author={Subramani, Pranav Shankar and Vergari, Antonio and Kamath, Gautam and Peharz, Robert and others}, booktitle={The 4th Workshop on Tractable Probabilistic Modeling}, year={2021}} -
TPM 2021
Is Parameter Learning via Weighted Model Integration Tractable?How does it take to perform tractable parameter learning for probabilistic models with algebraic constraints?[ pdf | bibtex | abstract ]Weighted Model Integration (WMI) is a recent and general formalism for reasoning over hybrid continuous/discrete probabilistic models with logical and algebraic constraints. While many works have focused on inference in WMI models, the challenges of learning them from data have received much less attention. Our contribution is twofold. First, we provide novel theoretical insights on the problem of estimating the parameters of these models from data in a tractable way, generalizing previous results on maximum-likelihood estimation (MLE) to the broader family of log-linear WMI models. Second, we show how our results on WMI can characterize the tractability of inference and MLE for another widely used class of probabilistic models, Hinge Loss Markov Random Fields (HL-MRFs). Specifically, we bridge these two areas of research by reducing marginal inference in HL-MRFs to WMI inference, and thus we open up new interesting applications for both model classes.@inproceedings{zeng2021parameter, title={Is Parameter Learning via Weighted Model Integration Tractable?}, author={Zeng, Zhe and Morettin, Paolo and Yan, Fanqi and Vergari, Antonio and Passerini, Andrea and Van den Broeck, Guy}, booktitle={The 4th Workshop on Tractable Probabilistic Modeling}, year={2021}} -
EACL 2021
An Empirical Study on the Generalization Power of Neural Representations Learned via Visual Guessing GamesCan guessing games help intelligent agent learn better perceptual grounding and question answering skills?[ pdf | bibtex | abstract ]Guessing games are a prototypical instance of the "learning by interacting" paradigm. This work investigates how well an artificial agent can benefit from playing guessing games when later asked to perform on novel NLP downstream tasks such as Visual Question Answering (VQA). We propose two ways to exploit playing guessing games: 1) a supervised learning scenario in which the agent learns to mimic successful guessing games and 2) a novel way for an agent to play by itself, called Self-play via Iterated Experience Learning (SPIEL). We evaluate the ability of both procedures to generalize: an in-domain evaluation shows an increased accuracy (+7.79) compared with competitors on the evaluation suite CompGuessWhat?!; a transfer evaluation shows improved performance for VQA on the TDIUC dataset in terms of harmonic average accuracy (+5.31) thanks to more fine-grained object representations learned via SPIEL.@inproceedings{suglia-etal-2021-empirical, title = "An Empirical Study on the Generalization Power of Neural Representations Learned via Visual Guessing Games", author = "Suglia, Alessandro and Bisk, Yonatan and Konstas, Ioannis and Vergari, Antonio and Bastianelli, Emanuele and Vanzo, Andrea and Lemon, Oliver", booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume", month = apr, year = "2021", address = "Online", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2021.eacl-main.183", doi = "10.18653/v1/2021.eacl-main.183", pages = "2135--2144"} -
UAI 2021
Tractable Computation of Expected KernelsUnder which conditions are kernel expectations, used in Stein divergences, MMD, etc., tractable?[ pdf | bibtex | abstract | supplemental ]Computing the expectation of kernel functions is a ubiquitous task in machine learning, with applications from classical support vector machines to exploiting kernel embeddings of distributions in probabilistic modeling, statistical inference, causal discovery, and deep learning. In all these scenarios, we tend to resort to Monte Carlo estimates as expectations of kernels are intractable in general. In this work, we characterize the conditions under which we can compute expected kernels exactly and efficiently, by leveraging recent advances in probabilistic circuit representations. We first construct a circuit representation for kernels and propose an approach to such tractable computation. We then demonstrate possible advancements for kernel embedding frameworks by exploiting tractable expected kernels to derive new algorithms for two challenging scenarios: 1) reasoning under missing data with kernel support vector regressors; 2) devising a collapsed black-box importance sampling scheme. Finally, we empirically evaluate both algorithms and show that they outperform standard baselines on a variety of datasets.@inproceedings{li2021tractable, title={Tractable computation of expected kernels}, author={Li, Wenzhe and Zeng, Zhe and Vergari, Antonio and Van den Broeck, Guy}, booktitle={Uncertainty in Artificial Intelligence}, pages={1163--1173}, year={2021}, organization={PMLR}} -
AAAI 2021 Demo Track
JUICE: A Julia Package for Logic and Probabilistic CircuitsA new library for reasoning and learning with probabilistic and logical circuits[ pdf | bibtex | abstract ]JUICE is an open-source Julia package providing tools for logic and probabilistic reasoning and learning based on logic circuits (LCs) and probabilistic circuits (PCs). It provides a range of efficient algorithms for probabilistic inference queries, such as computing marginal probabilities (MAR), as well as many more advanced queries. Certain structural circuit properties are needed to achieve this tractability, which JUICE helps validate. Additionally, it supports several parameter and structure learning algorithms proposed in the recent literature. By leveraging parallelism (on both CPU and GPU), JUICE provides a fast implementation of circuit-based algorithms, which makes it suitable for tackling large-scale datasets and models.@inproceedings{dang2021juice, title={Juice: A julia package for logic and probabilistic circuits}, author={Dang, Meihua and Khosravi, Pasha and Liang, Yitao and Vergari, Antonio and Van den Broeck, Guy}, booktitle={Proceedings of the 35th AAAI Conference on Artificial Intelligence (Demo Track)}, year={2021}} -
IJAR 2021
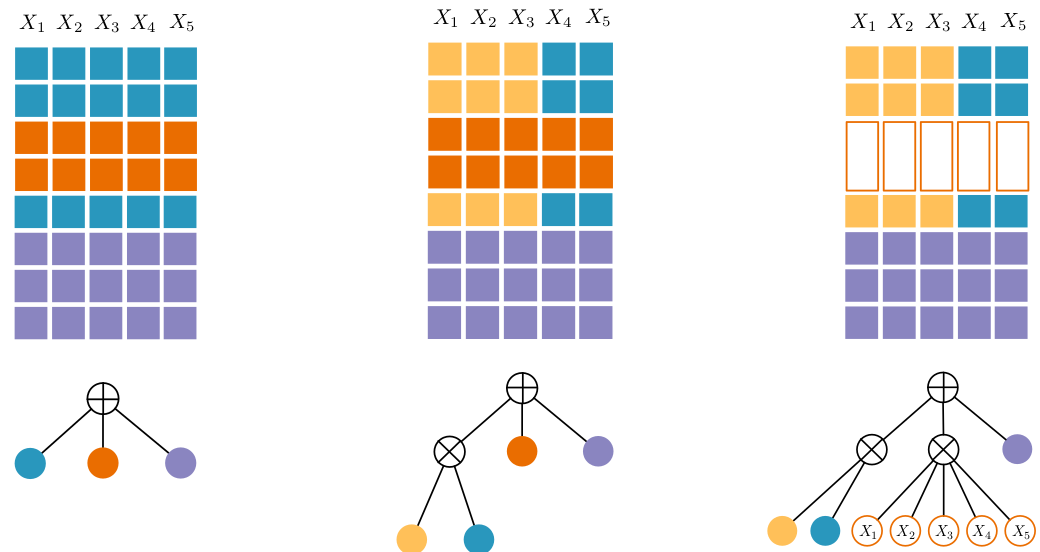
Conditional Sum-Product Networks: Modular Probabilistic Circuits via Gate FunctionsJournal version of the PGM2020 paper, containing more experiments and a cool VAE+ conditional SPN hybrid![ pdf | bibtex | abstract ]While probabilistic graphical models are a central tool for reasoning under uncertainty in AI, they are in general not as expressive as deep neural models, and inference is notoriously hard and slow. In contrast, deep probabilistic models such as sum-product networks (SPNs) capture joint distributions and ensure tractable inference, but still lack the expressive power of intractable models based on deep neural networks. In this paper, we introduce conditional SPNs (CSPNs)—conditional density estimators for multivariate and potentially hybrid domains—and develop a structure-learning approach that derives both the structure and parameters of CSPNs from data. To harness the expressive power of deep neural networks (DNNs), we also show how to realize CSPNs by conditioning the parameters of vanilla SPNs on the input using DNNs as gate functions. In contrast to SPNs whose high-level structure can not be explicitly manipulated, CSPNs can naturally be used as tractable building blocks of deep probabilistic models whose modular structure maintains high-level interpretability. In experiments, we demonstrate that CSPNs are competitive with other probabilistic models and yield superior performance on structured prediction, conditional density estimation, auto-regressive image modeling, and multilabel image classification. In particular, we show that employing CSPNs as encoders and decoders within variational autoencoders can help to relax the commonly used mean field assumption and in turn improve performance.@article{shao2021conditional, title = {Conditional sum-product networks: Modular probabilistic circuits via gate functions}, journal = {International Journal of Approximate Reasoning},volume = {140}, pages = {298-313}, year = {2022}, issn = {0888-613X}, doi = {https://doi.org/10.1016/j.ijar.2021.10.011}, url = {https://www.sciencedirect.com/science/article/pii/S0888613X21001766}, author = {Xiaoting Shao and Alejandro Molina and Antonio Vergari and Karl Stelzner and Robert Peharz and Thomas Liebig and Kristian Kersting}} -
IJAR 2022
Strudel: A fast and accurate learner of structured-decomposable probabilistic circuitsJournal version of the PGM2020 paper, containing more experiments and an in-depth discussion.[ pdf | bibtex | abstract ]Probabilistic circuits (PCs) represent a probability distribution as a computational graph. Enforcing structural properties on these graphs guarantees that several inference scenarios become tractable. Among these properties, structured decomposability is a particularly appealing one: it enables the efficient and exact computations of the probability of complex logical formulas, and can be used to reason about the expected output of certain predictive models under missing data. This paper proposes Strudel, a simple, fast and accurate learning algorithm for structured-decomposable PCs. Compared to prior work for learning structured-decomposable PCs, Strudel delivers more accurate single PC models in fewer iterations, and dramatically scales learning when building ensembles of PCs. It achieves this scalability by exploiting another structural property of PCs, called determinism, and by sharing the same computational graph across mixture components. We show these advantages on standard density estimation benchmarks and challenging inference scenarios.@article{dang2022strudel, title = {Strudel: A fast and accurate learner of structured-decomposable probabilistic circuits}, journal = {International Journal of Approximate Reasoning},volume = {140}, pages = {92-115}, year = {2022}, doi = {https://doi.org/10.1016/j.ijar.2021.09.012}, url = {https://www.sciencedirect.com/science/article/pii/S0888613X21001547},author = {Meihua Dang and Antonio Vergari and Guy {Van den Broeck}}} - 2020
-
NeurIPS 2020
Probabilistic Inference with Algebraic Constraints: Theoretical Limits and Practical ApproximationsWe exactly trace the boundaries of tractability of probabilistic inference with algebraic constraints and propose an efficient approximate solver.[ pdf | bibtex | abstract ]Weighted model integration (WMI) is a framework to perform advanced probabilistic inference on hybrid domains, i.e., on distributions over mixed continuous-discrete random variables and in presence of complex logical and arithmetic constraints. In this work, we advance the WMI framework on both the theoretical and algorithmic side. First, we exactly trace the boundaries of tractability for WMI inference by proving that to be amenable to exact and efficient inference a WMI problem has to posses a tree-shaped structure with logarithmic diameter. While this result deepens our theoretical understanding of WMI it hinders the practical applicability of exact WMI solvers to real-world problems. To overcome this, we propose the first approximate WMI solver that does not resort to sampling, but performs exact inference on one approximate models. Our solution performs message passing in a relaxed problem structure iteratively to recover certain lost dependencies and, as our experiments suggest, is competitive with other SOTA WMI solvers.@article{zeng2020probabilistic, title={Probabilistic Inference with Algebraic Constraints: Theoretical Limits and Practical Approximations}, author={Zeng, Zhe and Morettin, Paolo and Yan, Fanqi and Vergari, Antonio and Van den Broeck, Guy}, journal={Advances in Neural Information Processing Systems}, volume={33}, year={2020}}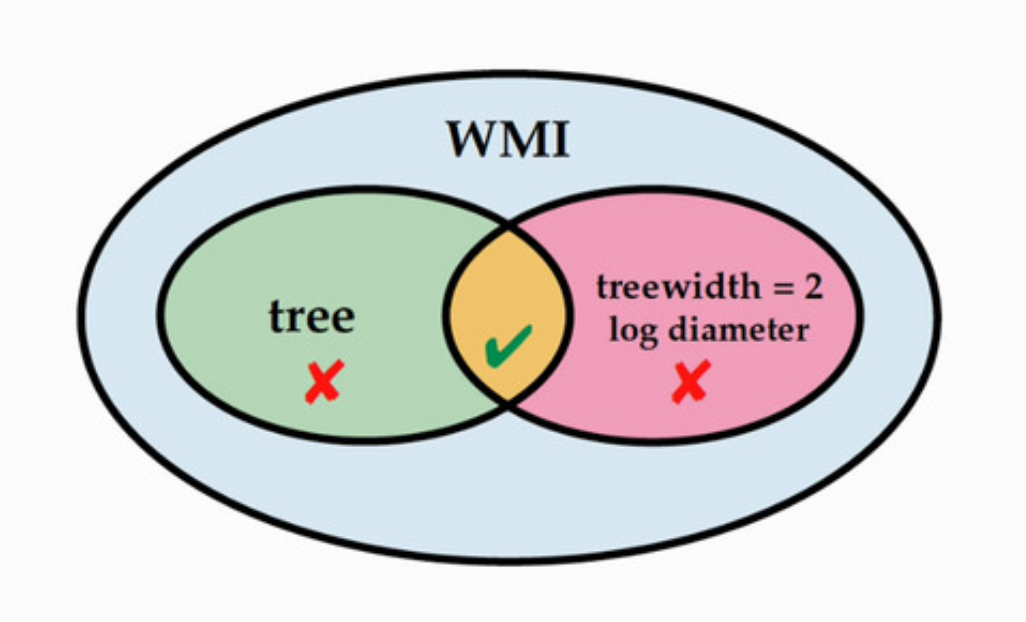
-
COLING 2020
Imagining Grounded Conceptual Representations from Perceptual Information in Situated Guessing GamesRegularized autoencoders can be effectively used to imagine embeddings that are category- and context-aware and help zero-shot generalization in guessing games.[ pdf | bibtex | abstract ]In visual guessing games, a Guesser has to identify a target object in a scene by asking questions to an Oracle. An effective strategy for the players is to learn conceptual representations of objects that are both discriminative and expressive enough to ask questions and guess correctly. However, as shown by Suglia et al. (2020), existing models fail to learn truly multi-modal representations, relying instead on gold category labels for objects in the scene both at training and inference time. This provides an unnatural performance advantage when categories at inference time match those at training time, and it causes models to fail in more realistic "zero-shot" scenarios where out-of-domain object categories are involved. To overcome this issue, we introduce a novel "imagination" module based on Regularized Auto-Encoders, that learns context-aware and category-aware latent embeddings without relying on category labels at inference time. Our imagination module outperforms state-of-the-art competitors by 8.26% gameplay accuracy in the CompGuessWhat?! zero-shot scenario (Suglia et al., 2020), and it improves the Oracle and Guesser accuracy by 2.08% and 12.86% in the GuessWhat?! benchmark, when no gold categories are available at inference time. The imagination module also boosts reasoning about object properties and attributes.@article{suglia2020imagining, title={Imagining Grounded Conceptual Representations from Perceptual Information in Situated Guessing Games}, author={Suglia, Alessandro and Vergari, Antonio and Konstas, Ioannis and Bisk, Yonatan and Bastianelli, Emanuele and Vanzo, Andrea and Lemon, Oliver}, journal={COLING}, year={2020}}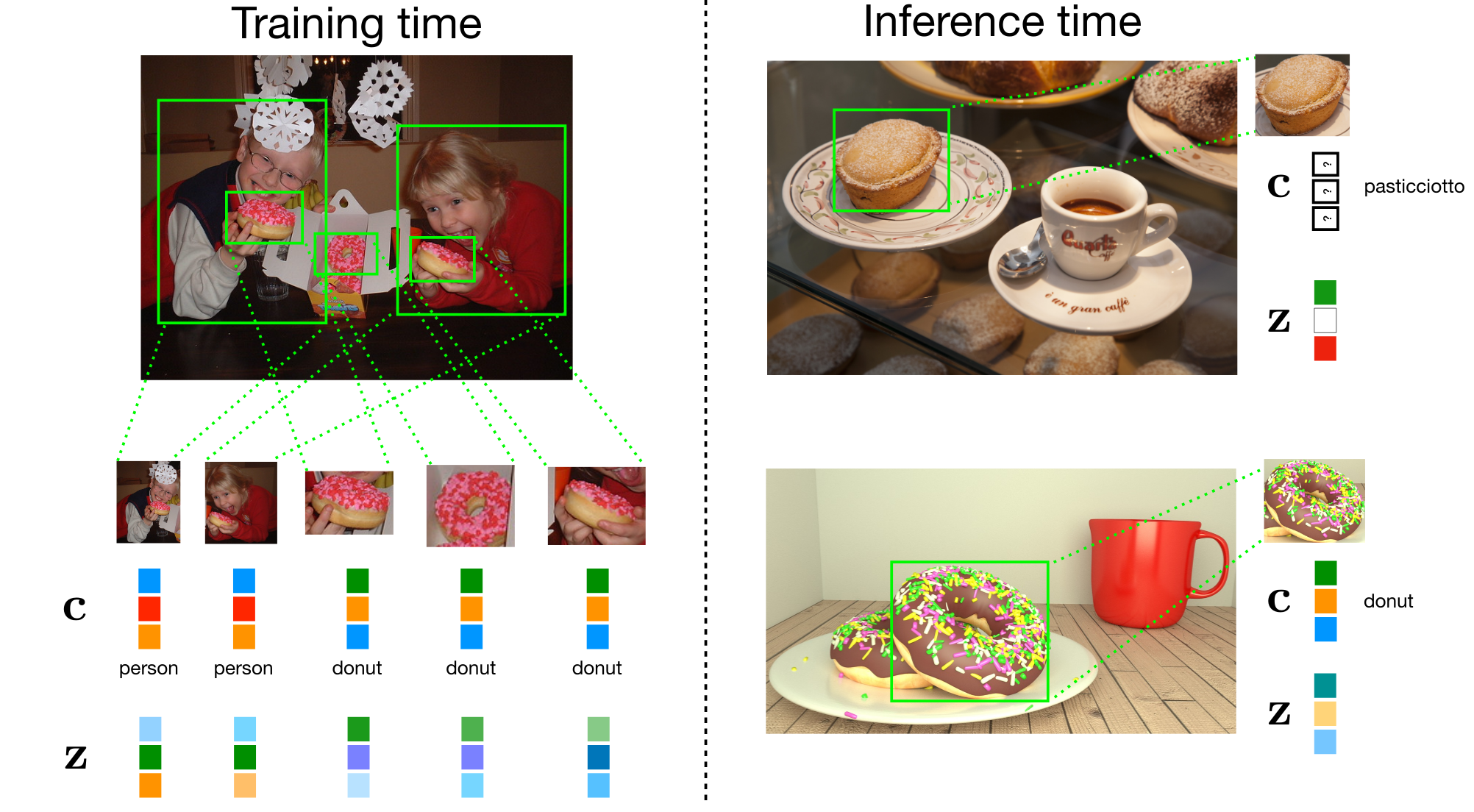
-
ArteMISS @ ICML 2020
Handling Missing Data in Decision Trees: A Probabilistic ApproachMissing values at training and test time for decision trees can be dealt with in a principled and efficient way by computing their expected predictions and training their expected loss.[ pdf | bibtex | abstract ]Decision trees are a popular family of models due to their attractive properties such as interpretability and ability to handle heterogeneous data. Concurrently, missing data is a prevalent occurrence that hinders performance of machine learning models. As such, handling missing data in decision trees is a well studied problem. In this paper, we tackle this problem by taking a probabilistic approach. At deployment time, we use tractable density estimators to compute the" expected prediction" of our models. At learning time, we fine-tune parameters of already learned trees by minimizing their" expected prediction loss" wrt\our density estimators. We provide brief experiments showcasing effectiveness of our methods compared to few baselines.@article{khosravi2020handling, title={Handling missing data in decision trees: A probabilistic approach}, author={Khosravi, Pasha and Vergari, Antonio and Choi, YooJung and Liang, Yitao and Broeck, Guy Van den}, journal={arXiv preprint arXiv:2006.16341}, year={2020}} -
ICML 2020
Einsum Networks: Fast and Scalable Learning of Tractable Probabilistic CircuitsScaling inference in probabilistic circuits by combining a large number of arithmetic operations in a single monolithic einsum operation, leading to two orders of magnitude speedups and memory savings.[ pdf | bibtex | abstract ]Probabilistic circuits (PCs) are a promising avenue for probabilistic modeling, as they permit a wide range of exact and efficient inference routines. Recent``deep-learning-style''implementations of PCs strive for a better scalability, but are still difficult to train on real-world data, due to their sparsely connected computational graphs. In this paper, we propose Einsum Networks (EiNets), a novel implementation design for PCs, improving prior art in several regards. At their core, EiNets combine a large number of arithmetic operations in a single monolithic einsum-operation, leading to speedups and memory savings of up to two orders of magnitude, in comparison to previous implementations. As an algorithmic contribution, we show that the implementation of Expectation-Maximization (EM) can be simplified for PCs, by leveraging automatic differentiation. Furthermore, we demonstrate that EiNets scale well to datasets which were previously out of reach, such as SVHN and CelebA, and that they can be used as faithful generative image models.@article{peharz2020einsum, title={Einsum Networks: Fast and Scalable Learning of Tractable Probabilistic Circuits}, author={Peharz, Robert and Lang, Steven and Vergari, Antonio and Stelzner, Karl and Molina, Alejandro and Trapp, Martin and Broeck, Guy Van den and Kersting, Kristian and Ghahramani, Zoubin}, journal={arXiv preprint arXiv:2004.06231}, year={2020}}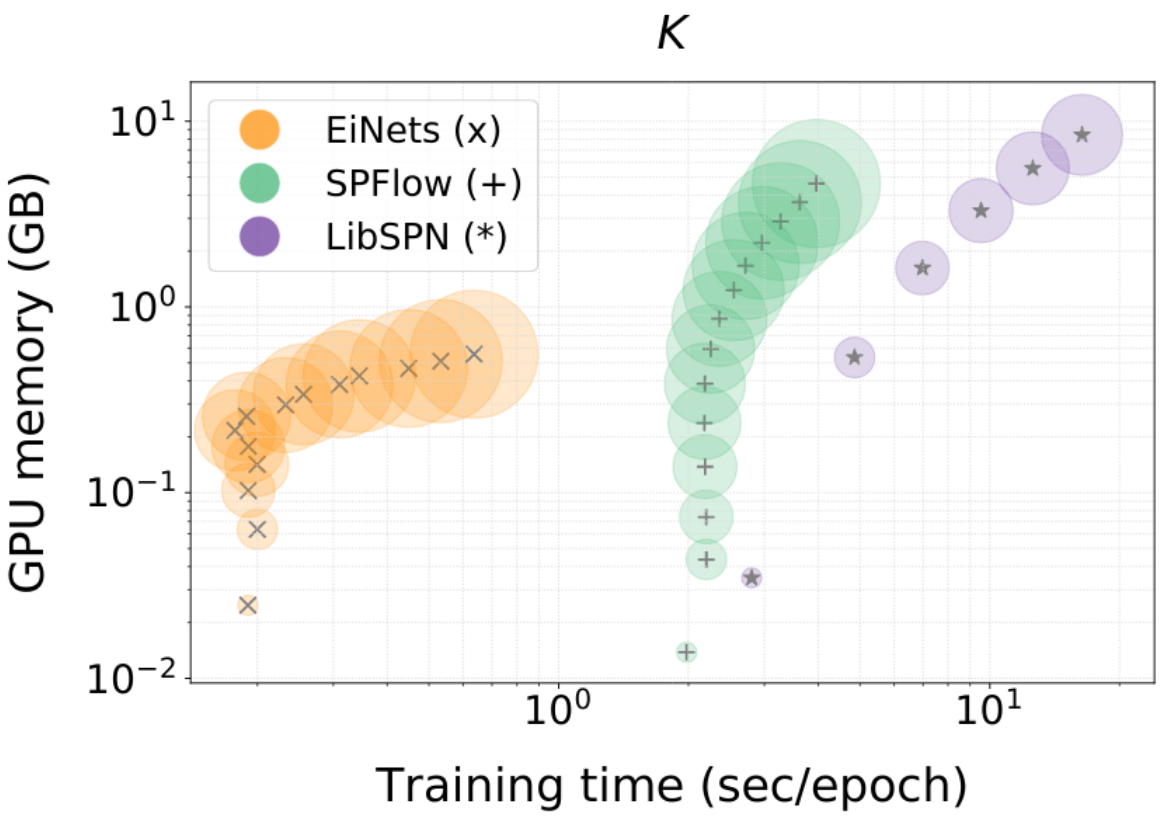
-
ICML 2020
Scaling up Hybrid Probabilistic Inference with Logical and Arithmetic Constraints via Message PassingTracing the tractability boundaries of probabilistic inference with complex logical constraints over heterogenous data, and distilling the first (tractable) message passing algorithm for it.[ pdf | bibtex | abstract ]Weighted model integration (WMI) is an appealing framework for probabilistic inference: it allows for expressing the complex dependencies in real-world problems, where variables are both continuous and discrete, via the language of Satisfiability Modulo Theories (SMT), as well as to compute probabilistic queries with complex logical and arithmetic constraints. Yet, existing WMI solvers are not ready to scale to these problems. They either ignore the intrinsic dependency structure of the problem entirely, or they are limited to overly restrictive structures. To narrow this gap, we derive a factorized WMI computation enabling us to devise a scalable WMI solver based on message passing, called MP-WMI. Namely, MP-WMI is the first WMI solver that can (i) perform exact inference on the full class of tree-structured WMI problems, and (ii) perform inter-query amortization, e.g., to compute all marginal densities simultaneously. Experimental results show that our solver dramatically outperforms the existingWMI solvers on a large set of benchmarks.@article{zeng2020scaling, title={Scaling up Hybrid Probabilistic Inference with Logical and Arithmetic Constraints via Message Passing}, author={Zeng, Zhe and Morettin, Paolo and Yan, Fanqi and Vergari, Antonio and Broeck, Guy Van den}, journal={arXiv preprint arXiv:2003.00126}, year={2020}}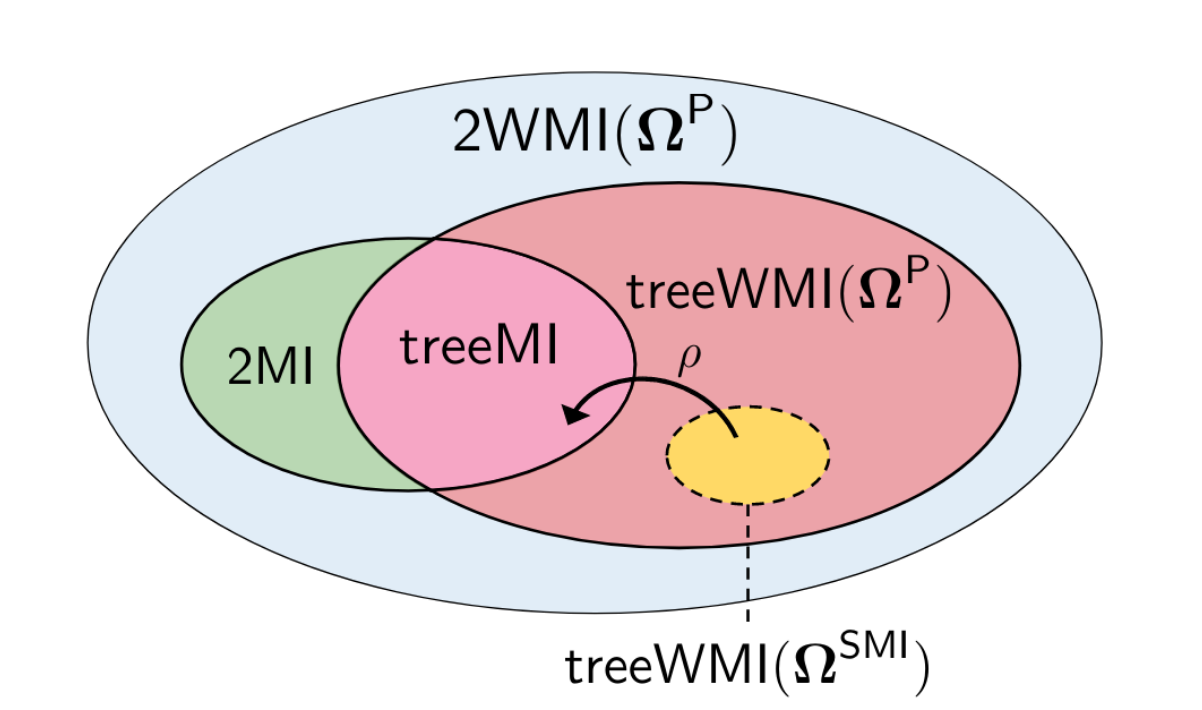
-
PGM 2020
Conditional Sum-Product Networks: Imposing Structure on Deep Probabilistic ArchitecturesCSPNs are (conditionally) smooth and decomposable circuits directly modeling conditional distributions. Which is arguably what people want when interested only in (structured output) prediction tasks.[ pdf | bibtex | abstract ]Bayesian networks are a central tool in machine learning and artificial intelligence, and make use of conditional independencies to impose structure on joint distributions. However, they are generally not as expressive as deep learning models and inference is hard and slow. In contrast, deep probabilistic models such as sum-product networks (SPNs) capture joint distributions in a tractable fashion, but use little interpretable structure. Here, we extend the notion of SPNs towards conditional distributions, which combine simple conditional models into high-dimensional ones. As shown in our experiments, the resulting conditional SPNs can be naturally used to impose structure on deep probabilistic models, allow for mixed data types, while maintaining fast and efficient inference.@article{shao2020conditional,
title={Conditional Sum-Product Networks: Imposing Structure on Deep Probabilistic Architectures},
author={Shao, Xiaoting and Molina, Alejandro and Vergari, Antonio and Stelzner, Karl and Peharz, Robert and Liebig, Thomas and Kersting, Kristian},
journal={PGM},
year={2020}}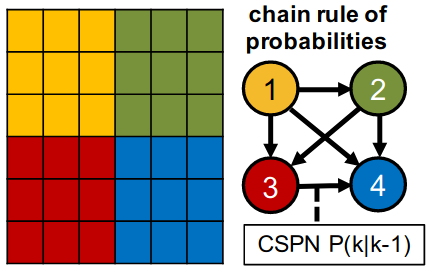
-
PGM 2020
Strudel: Learning Structured-Decomposable Probabilistic CircuitsWe introduce a simple, fast and accurate learning algorithm for structured-decomposable probabilistic circuits (PCs), STRUDEL, which dramatically scales learning when building ensembles of PCs[ pdf | bibtex | abstract ]Probabilistic circuits (PCs) represent a probability distribution as a computational graph. Enforcing structural properties on these graphs guarantees that several inference scenarios become tractable. Among these properties, structured decomposability is a particularly appealing one: it enables the efficient and exact computations of the probability of complex logical formulas, and can be used to reason about the expected output of certain predictive models under missing data. This paper proposes Strudel, a simple, fast and accurate learning algorithm for structured-decomposable PCs. Compared to prior work for learning structured-decomposable PCs, Strudel delivers more accurate single PC models in fewer iterations, and dramatically scales learning when building ensembles of PCs. It achieves this scalability by exploiting another structural property of PCs, called determinism, and by sharing the same computational graph across mixture components. We show these advantages on standard density estimation benchmarks and challenging inference scenarios.@article{dang2020strudel, title={Strudel: Learning Structured-Decomposable Probabilistic Circuits}, author={Dang, Meihua and Vergari, Antonio and Broeck, Guy Van den}, journal={PGM}, year={2020}}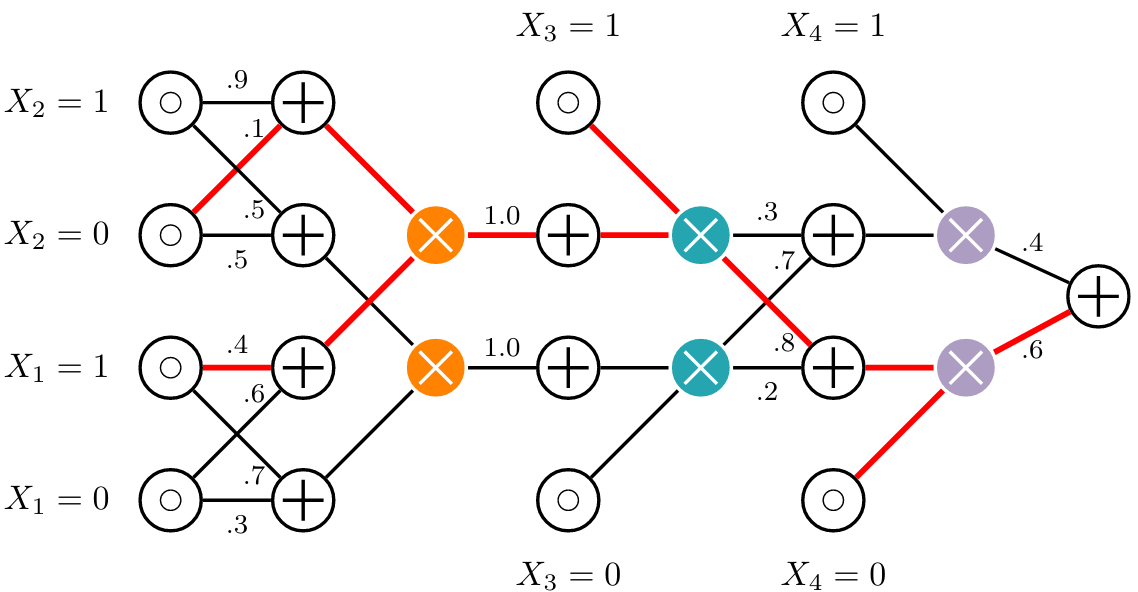
-
ICLR 2020
From Variational to Deterministic AutoencodersIs the success of VAEs as generative models due to variational Bayes? We show that deterministic and regularized (even implicitly) autoencoders can learn an equally smooth and meaningful latent space. But how to sample without a prior? A simple ex-post density estimation step is enough to deliver equally good or better samples than VAEs![ pdf | bibtex | abstract ]Variational Autoencoders (VAEs) provide a theoretically-backed and popular framework for deep generative models. However, learning a VAE from data poses still unanswered theoretical questions and considerable practical challenges. In this work, we propose an alternative framework for generative modeling that is simpler, easier to train, and deterministic, yet has many of the advantages of the VAE. We observe that sampling a stochastic encoder in a Gaussian VAE can be interpreted as simply injecting noise into the input of a deterministic decoder. We investigate how substituting this kind of stochasticity, with other explicit and implicit regularization schemes, can lead to an equally smooth and meaningful latent space without having to force it to conform to an arbitrarily chosen prior. To retrieve a generative mechanism to sample new data points, we introduce an ex-post density estimation step that can be readily applied to the proposed framework as well as existing VAEs, improving their sample quality. We show, in a rigorous empirical study, that the proposed regularized deterministic autoencoders are able to generate samples that are comparable to, or better than, those of VAEs and more powerful alternatives when applied to images as well as to structured data such as molecules.@inproceedings{ghosh2020iclr,
title={From Variational to Deterministic Autoencoders},
author={Partha Ghosh, Mehdi S. M. Sajjadi, Antonio Vergari, Michael Black, Bernhard Scholkopf},
booktitle={International Conference on Learning and Representations (ICLR)}, year={2020}}
- 2019
-
KR2ML@NeurIPS 2019
Hybrid Probabilistic Inference with Logical Constraints: Tractability and Message-PassingTracing the tractability boundaries of probabilistic inference with complex logical constraints over heterogenous data, and distilling the first (tractable) message passing algorithm for it.[ pdf | bibtex | abstract ]Weighted model integration (WMI) is a very appealing framework for probabilistic inference: it allows to express the complex dependencies of real-world hybrid scenarios where variables are heterogeneous in nature (both continuous and discrete) via the language of Satisfiability Modulo Theories (SMT); as well as computing probabilistic queries with arbitrarily complex logical constraints. Recent work has shown WMI inference to be reducible to a model integration (MI) problem, under some assumptions, thus effectively allowing hybrid probabilistic reasoning by volume computations. In this paper, we introduce a novel formulation of MI via a message passing scheme that allows to efficiently compute the marginal densities and statistical moments of all the variables in linear time. As such, we are able to amortize inference for arbitrarily rich MI queries when they conform to the problem structure, here represented as the primal graph associated to the SMT formula. Furthermore, we theoretically trace the tractability boundaries of exact MI. Indeed, we prove that in terms of the structural requirements on the primal graph that make our MI algorithm tractable-bounding its diameter and treewidth-the bounds are not only sufficient, but necessary for tractable inference via MI.@inproceedings{zeng2019hybrid,
title={Hybrid Probabilistic Inference with Logical Constraints: Tractability and Message-Passing},
author={Zeng, Zhe and Yan, Fanqi and Morettin, Paolo and Vergari, Antonio and Broeck, Guy Van den},
booktitle={Knowledge Representation & Reasoning Meets Machine Learning},
year={2019}}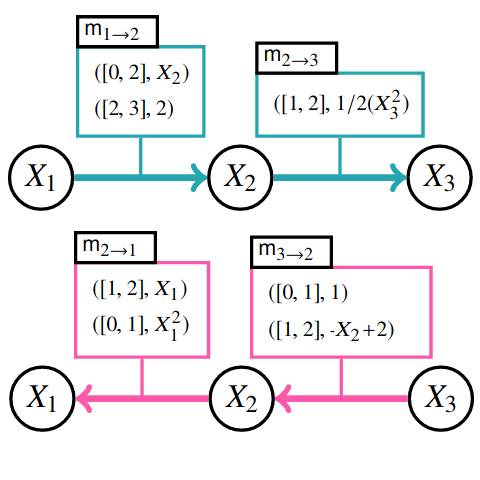
-
NeurIPS 2019
On Tractable Computation of Expected PredictionsTractable advanced probabilistic reasoning over predictive models can be unlocked by representing generative models and discriminative models as suitable circuits and pairing them together.[ pdf | bibtex | abstract | supplemental ]Computing expected predictions of discriminative models is a fundamental task in machine learning that appears in many interesting applications such as fairness, handling missing values, and data analysis. Unfortunately, computing expectations of a discriminative model with respect to a probability distribution defined by an arbitrary generative model has been proven to be hard in general. In fact, the task is intractable even for simple models such as logistic regression and a naive Bayes distribution. In this paper, we identify a pair of generative and discriminative models that enables tractable computation of expectations, as well as moments of any order, of the latter with respect to the former in case of regression. Specifically, we consider expressive probabilistic circuits with certain structural constraints that support tractable probabilistic inference. Moreover, we exploit the tractable computation of high-order moments to derive an algorithm to approximate the expectations for classification scenarios in which exact computations are intractable. Our framework to compute expected predictions allows for handling of missing data during prediction time in a principled and accurate way and enables reasoning about the behavior of discriminative models. We empirically show our algorithm to consistently outperform standard imputation techniques on a variety of datasets. Finally, we illustrate how our framework can be used for exploratory data analysis.@incollection{NIPS2019_9296,
title = {On Tractable Computation of Expected Predictions},
author = {Khosravi, Pasha and Choi, YooJung and Liang, Yitao and Vergari, Antonio and Van den Broeck, Guy},
booktitle = {Advances in Neural Information Processing Systems 32},
editor = {H. Wallach and H. Larochelle and A. Beygelzimer and F. d\textquotesingle Alch\'{e}-Buc and E. Fox and R. Garnett},
pages = {11167--11178},
year = {2019},
publisher = {Curran Associates, Inc.},
url = {http://papers.nips.cc/paper/9296-on-tractable-computation-of-expected-predictions.pdf}}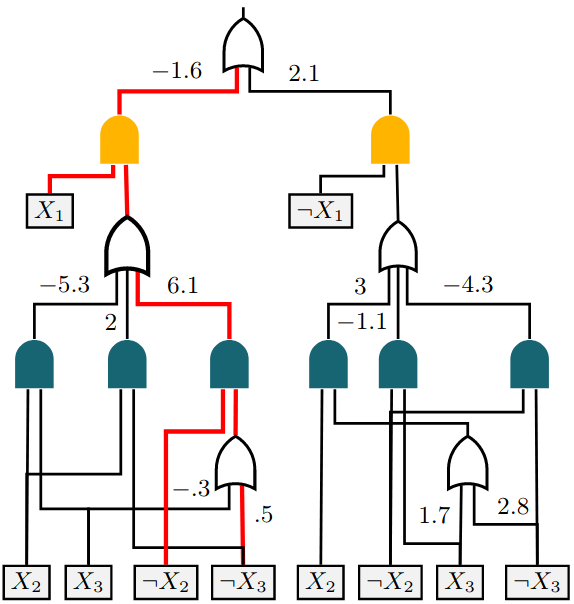
-
AAAI 2019
Automatic Bayesian density analysisTowards an unsupervised automated statistician: a single tractable probabilistic model exploitable for exploratory data analysis, handling noisy, anomalous and missing values and inferring statistical data types.[ pdf | bibtex | code | abstract | supplemental ]Making sense of a dataset in an automatic and unsupervised fashion is a challenging problem in statistics and AI. Classical approaches for exploratory data analysis are usually not flexible enough to deal with the uncertainty inherent to real-world data: they are often restricted to fixed latent interaction models and homogeneous likelihoods; they are sensitive to missing, corrupt and anomalous data; moreover, their expressiveness generally comes at the price of intractable inference. As a result, supervision from statisticians is usually needed to find the right model for the data. However, since domain experts are not necessarily also experts in statistics, we propose Automatic Bayesian Density Analysis (ABDA) to make exploratory data analysis accessible at large. Specifically, ABDA allows for automatic and efficient missing value estimation, statistical data type and likelihood discovery, anomaly detection and dependency structure mining, on top of providing accurate density estimation. Extensive empirical evidence shows that ABDA is a suitable tool for automatic exploratory analysis of mixed continuous and discrete tabular data.@inproceedings{vergari2019abda,
title={Automatic Bayesian density analysis},
author={Vergari, Antonio and Molina, Alejandro and Peharz, Robert and Ghahramani, Zoubin and Kersting, Kristian and Valera, Isabel},
booktitle={Thirty-three AAAI Conference on Artificial Intelligence (AAAI)}, year={2019}}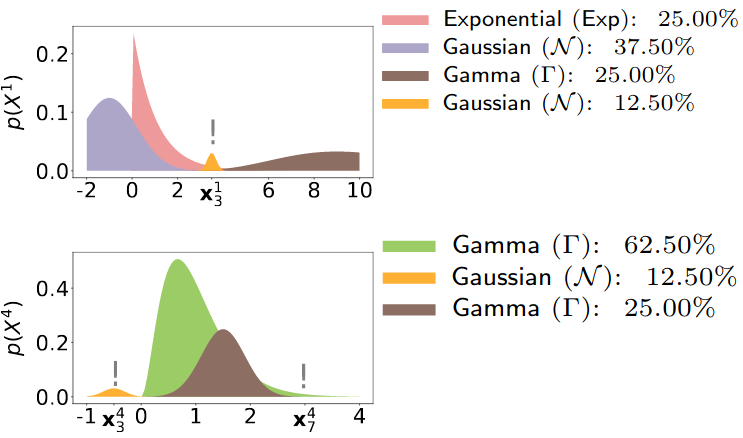
-
UAI 2019
Random Sum-Product Networks: A Simple and Effective Approach to Probabilistic Deep LearningDo we really need structure learning for SPNs? (good question as it generally hinders a tighter integration with deep learning schemes) Randomised and Tensorised SPNs waive the need for it while delivering accurate and calibrated density estimators and classifiers.[ pdf | bibtex | code | abstract | supplemental ]Sum-product networks (SPNs) are expressive probabilistic models with a rich set of exact and efficient inference routines. However, in order to guarantee exact inference, they require specific structural constraints, which complicate learning SPNs from data. Thereby, most SPN structure learners proposed so far are tedious to tune, do not scale easily, and are not easily integrated with deep learning frameworks. In this paper, we follow a simple “deep learning” approach, by generating unspecialized random structures, scalable to millions of parameters, and subsequently applying GPU-based optimization. Somewhat surprisingly, our models often perform on par with state-ofthe-art SPN structure learners and deep neural networks on a diverse range of generative and discriminative scenarios. At the same time, our models yield well-calibrated uncertainties, and stand out among most deep generative and discriminative models in being robust to missing features and being able to detect anomalies.@inproceedings{peharz2019random,
title={Random sum-product networks: A simple and effective approach to probabilistic deep learning},
author={Peharz, Robert and Vergari, Antonio and Stelzner, Karl and Molina, Alejandro and Shao, Xiaoting and Trapp, Martin and Kersting, Kristian and Ghahramani, Zoubin},
booktitle={Conference on Uncertainty in Artificial Intelligence (UAI)}, year={2019}}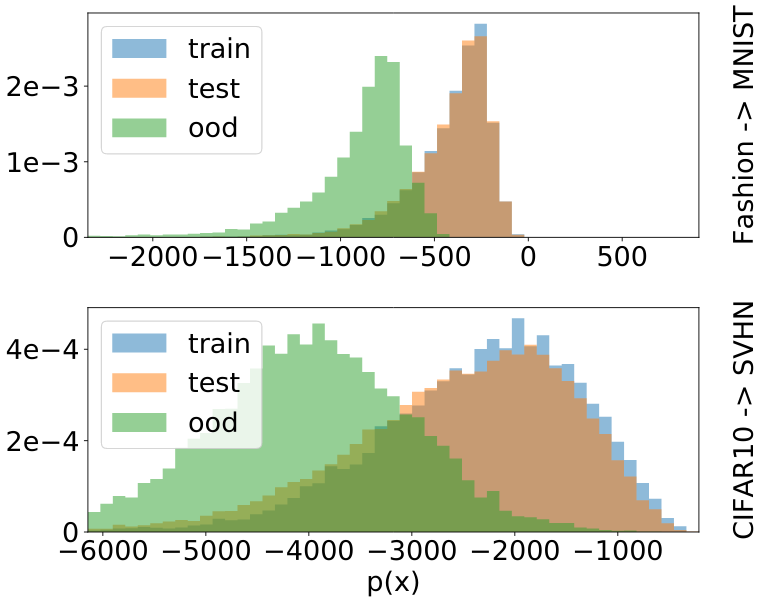
-
Machine Learning Journal 2019
Visualizing and understanding Sum-Product NetworksWhich representations do Sum-Product Networks learn? Visualizing the learned features and collecting them into embeddings sheds a light on it and opens the way to explainability, and representation learning as well.[ pdf | bibtex | code | abstract ]Sum-Product Networks (SPNs) are deep tractable probabilistic models by which several kinds of inference queries can be answered exactly and in a tractable time. They have been largely used as black box density estimators, assessed by comparing their likelihood scores on different tasks. In this paper we explore and exploit the inner representations learned by SPNs. By taking a closer look at the inner workings of SPNs, we aim to better understand what and how meaningful the representations they learn are, as in a classic Representation Learning framework. We firstly propose an interpretation of SPNs as Multi-Layer Perceptrons, we then devise several criteria to extract representations from SPNs and finally we empirically evaluate them in several (semi-)supervised tasks showing they are competitive against classical feature extractors like RBMs, DBNs and deep probabilistic autoencoders, like MADEs and VAEs.@Article{Vergari2019,author="Vergari, Antonio and Di Mauro, Nicola and Esposito, Floriana",
title="Visualizing and understanding Sum-Product Networks",
journal="Machine Learning",
year="2019", month="Apr",
day="01",
volume="108",
number="4",
pages="551--573",
issn="1573-0565",
doi="10.1007/s10994-018-5760-y",
url="https://doi.org/10.1007/s10994-018-5760-y"}
-
Journal of Intelligent Information Systems
Ensembles of density estimators for positive-unlabeled learningExtended journal version of "Density Estimators for Positive-Unlabeled Learning"[ pdf | bibtex | abstract ]Positive-Unlabeled (PU) learning works by considering a set of positive samples, and a (usually larger) set of unlabeled ones. This challenging setting requires algorithms to cleverly exploit dependencies hidden in the unlabeled data in order to build models able to accurately discriminate between positive and negative samples. We propose to exploit probabilistic generative models to characterize the distribution of the positive samples, and to label as reliable negative samples those that are in the lowest density regions with respect to the positive ones. The overall framework is flexible enough to be applied to many domains by leveraging tools provided by years of research from the probabilistic generative model community. Results on several benchmark datasets show the performance and flexibility of the proposed approach.@article{basile2019ensembles,
title={Ensembles of density estimators for positive-unlabeled learning},
author={Basile, TMA and Di Mauro, N and Esposito, F and Ferilli, S and Vergari, A},
journal={Journal of Intelligent Information Systems},
pages={1--19},
year={2019},
publisher={Springer}} - 2018
-
AAAI 2018
Sum-product autoencoding: Encoding and decoding representations using sum-product networksSPNs can be exploited as embedding extractors and decoders as well and these embeddings are highly informative and predictive for downstream tasks. And the associated features are explainable.[ pdf | bibtex | code | abstract ]Sum-Product Networks (SPNs) are a deep probabilistic architecture that up to now has been successfully employed for tractable inference. Here, we extend their scope towards unsupervised representation learning: we encode samples into continuous and categorical embeddings and show that they can also be decoded back into the original input space by leveraging MPE inference. We characterize when this Sum-Product Autoencoding (SPAE) leads to equivalent reconstructions and extend it towards dealing with missing embedding information. Our experimental results on several multi-label classification problems demonstrate that SPAE is competitive with state-of-the-art autoencoder architectures, even if the SPNs were never trained to reconstruct their inputs.@inproceedings{vergari2018sum,
title={Sum-product autoencoding: Encoding and decoding representations using sum-product networks},
author={Vergari, Antonio and Peharz, Robert and Di Mauro, Nicola and Molina, Alejandro and Kersting, Kristian and Esposito, Floriana},
booktitle={Thirty-Second AAAI Conference on Artificial Intelligence},
year={2018}}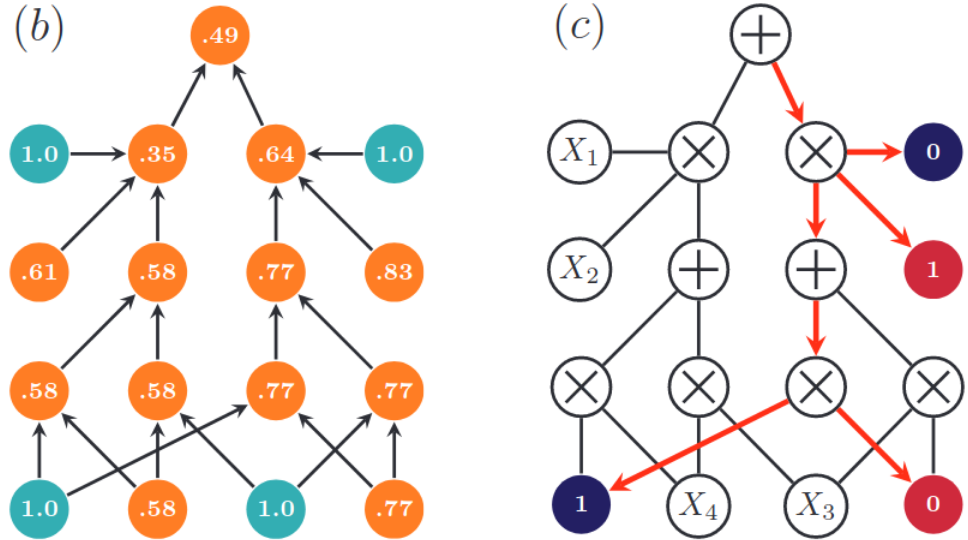
-
AAAI 2018
Mixed sum-product networks: A deep architecture for hybrid domainsCan we perform tractable probabilistic inference on heterogeneous data and being agnostic to the marginal likelihood parametric forms? Mixed Sum-Product Networks allow to do that by modeling expressive piecewise polynomials of joint masses and densities as smooth and decomposable circuits.[ pdf | bibtex | code | abstract ]While all kinds of mixed data---from personal data, over panel and scientific data, to public and commercial data---are collected and stored, building probabilistic graphical models for these hybrid domains becomes more difficult. Users spend significant amounts of time in identifying the parametric form of the random variables (Gaussian, Poisson, Logit, etc.) involved and learning the mixed models. To make this difficult task easier, we propose the first trainable probabilistic deep architecture for hybrid domains that features tractable queries. It is based on Sum-Product Networks (SPNs) with piecewise polynomial leaf distributions together with novel nonparametric decomposition and conditioning steps using the Hirschfeld-Gebelein-Renyi Maximum Correlation Coefficient. This relieves the user from deciding a-priori the parametric form of the random variables but is still expressive enough to effectively approximate any distribution and permits efficient learning and inference. Our experiments show that the architecture, called Mixed SPNs, can indeed capture complex distributions across a wide range of hybrid domains.@inproceedings{molina2018mixed,
title={Mixed sum-product networks: A deep architecture for hybrid domains},
author={Molina, Alejandro and Vergari, Antonio and Di Mauro, Nicola and Natarajan, Sriraam and Esposito, Floriana and Kersting, Kristian},
booktitle={Thirty-second AAAI conference on artificial intelligence},
year={2018}}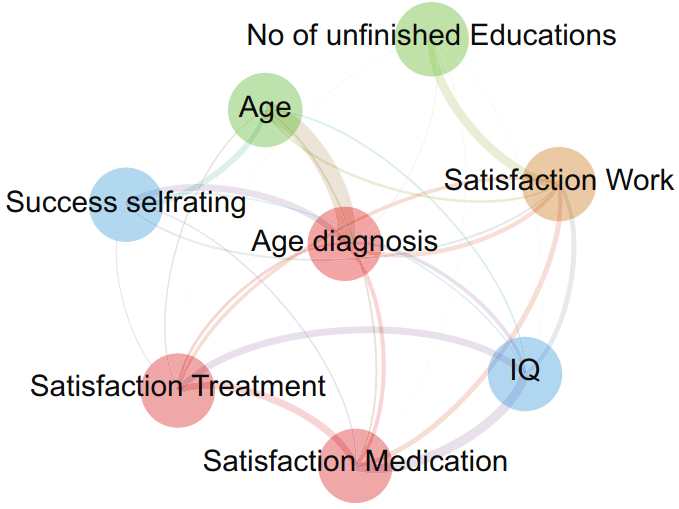
-
Bayesian Nonparametrics@NeurIPS 2018
Bayesian Nonparametric Hawkes ProcessesCombining Hawks Processes with Bayesian Nonparametric priors in an elegant and principled framework that generalizes many previous works and "fixes" others some not-so-principled attempts in the literature.[ pdf | bibtex ]@inproceedings{di2017alternative,
title={Alternative variable splitting methods to learn sum-product networks},
author={Di Mauro, Nicola and Esposito, Floriana and Ventola, Fabrizio G and Vergari, Antonio},
booktitle={Conference of the Italian Association for Artificial Intelligence},
pages={334--346},
year={2017},
organization={Springer}}
-
Intelligenza Artificiale 2018
Sum-Product Network structure learning by efficient product nodes discoveryExtended journal version of "Alternative Variable Splitting Methods to Learn Sum-Product Networks"[ pdf | bibtex | code | abstract ]Sum-Product Networks (SPNs) are recent deep probabilistic models providing exact and tractable inference. SPNs have been successfully employed as density estimators in several application domains. However, learning an SPN from high dimensional data still poses a challenge in terms of time complexity. This is due to the high cost of determining independencies among random variables (RVs) and sub-populations among samples, two operations that are repeated several times. Even one of the simplest greedy structure learner, LearnSPN, scales quadratically in the number of the variables to determine RVs independencies. In this work we investigate approximate but fast procedures to determine independencies among RVs whose complexity scales in sub-quadratic time. We propose two procedures: a random subspace approach and one that adopts entropy as a criterion to split RVs in linear time. Experimentalresults prove that LearnSPN equipped by our splitting procedures is ableto reduce learning and/or inference times while preserving comparable inference accuracy.@article{di2018sum,
title={Sum-Product Network structure learning by efficient product nodes discovery},
author={Di Mauro, Nicola and Esposito, Floriana and Ventola, Fabrizio Giuseppe and Vergari, Antonio},
journal={Intelligenza Artificiale},
volume={12},
number={2},
pages={143--159},
year={2018},
publisher={IOS Press}} - 2017
-
ECML-PKDD 2017
Fast and Accurate Density Estimation with Extremely Randomized Cutset NetworksHow to deliver state-of-the art density estimation in a fraction of the time of classical TPM learners? Mixtures of totally randomly conditioned Cutset Networks![ pdf | bibtex | code | abstract ]Cutset Networks (CNets) are density estimators leveraging context-specific independencies recently introduced to provide exact inference in polynomial time. Learning a CNet is done by firstly building a weighted probabilistic OR tree and then estimating tractable distributions as its leaves. Specifically, selecting an optimal OR split noderequires cubic time in the number of the data features, and even approximate heuristics still scale in quadratic time. We introduce Extremely Randomized Cutset Networks (XCNets), CNets whose OR tree is learned by performing random conditioning. This simple yet surprisingly effective approach reduces the complexity of OR node selection to constant time. While the likelihood of an XCNet is slightly worse than an optimally learned CNet, ensembles of XCNets outperform state-of-the-art density estimators on a series of standard benchmark datasets, yet employing only a fraction of the time needed to learn the competitors.@inproceedings{di2017fast,
title={Fast and accurate density estimation with extremely randomized cutset networks},
author={Di Mauro, Nicola and Vergari, Antonio and Basile, Teresa MA and Esposito, Floriana},
booktitle={Joint European conference on machine learning and knowledge discovery in databases},
pages={203--219},
year={2017},
organization={Springer}}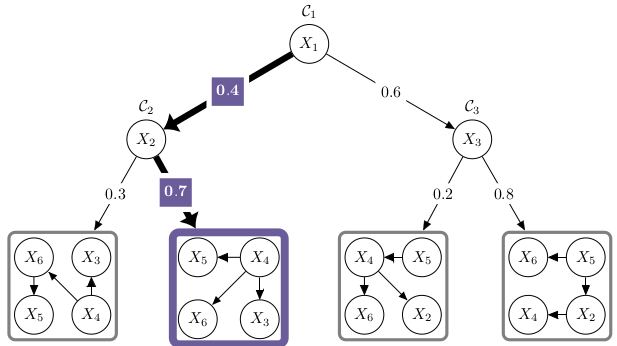
-
ICLR workshop 2017
Encoding and Decoding Representations with Sum- and Max-Product NetworksSum- and Max-Product Networks can be effectively exploited as autoencoders without the need of training them to reconstruct their input. These embeddings are cheap and surprisingly effective alternatives for structured output prediction tasks.[ pdf | bibtex | code | abstract ]Sum-Product Networks (SPNs) are deep density estimators allowing exact andtractable inference. While up to now SPNs have been employed as black-boxinference machines, we exploit them as feature extractors for unsupervised Rep-resentation Learning. Representations learned by SPNs are rich probabilistic andhierarchical part-based features. SPNs converted into Max-Product Networks(MPNs) provide a way to decode these representations back to the original inputspace. In extensive experiments, SPN and MPN encoding and decoding schemesprove highly competitive for Multi-Label Classification tasks.@article{Vergari2016b,
author = {Antonio Vergari and
Nicola Di Mauro and
Floriana Esposito},
title = {Towards Representation Learning with Tractable Probabilistic Models},
journal = {CoRR},
volume = {abs/1608.02341},
year = {2016},
url = {http://arxiv.org/abs/1608.02341},
timestamp = {Wed, 07 Jun 2017 14:41:08 +0200},
biburl = {http://dblp.uni-trier.de/rec/bib/journals/corr/VergariME16},
bibsource = {dblp computer science bibliography, http://dblp.org}}
-
Discovery Challenge@ECML-PKDD 2017 1st prize
End-to-end Learning of Deep Spatio-temporal Representations for Satellite Image Time Series ClassificationAn effective way to perform spectral image segmentation: pair a deep convolutional net with a collective classification approach![ pdf | bibtex | code | abstract ]In this paper we describe our first-place solution to the discovery challenge on time series land cover classification (TiSeLaC), organized in conjunction of ECML PKDD 2017. The challenge consists in predicting the Land Cover class of a set of pixels given their image time series data acquired by the satellites. We propose an end-to-end learning approach employing both temporal and spatial information and requiring very little data preprocessing and feature engineering. In this report we detail the architecture that ranked first—out of 21 teams—comprising modules using dense multi-layer perceptrons and one-dimensional convolutional neural networks. We discuss this architecture properties in detail as well as several possible enhancements.@inproceedings{di2017end,
title={End-to-end Learning of Deep Spatio-temporal Representations for Satellite Image Time Series Classification.},
author={Di Mauro, Nicola and Vergari, Antonio and Basile, Teresa Maria Altomare and Ventola, Fabrizio G and Esposito, Floriana},
booktitle={DC@ PKDD/ECML},
year={2017}}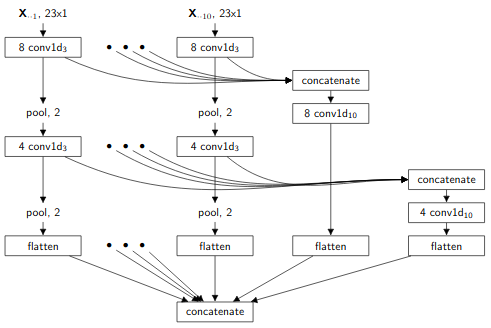
-
AIxIA 2017
Alternative Variable Splitting Methods to Learn Sum-Product NetworksGreedy top-down circuit structure learning can be slow due to independence tests. By approximating and randomizing them we can speed up learning. No free lunch: likelihoods degrade.[ pdf | bibtex | code | abstract ]Sum-Product Networks (SPNs) are recent deep probabilistic models providing exact and tractable inference. SPNs have been successfully employed as density estimators in several application domains. However, learning an SPN from high dimensional data still poses a challenge in terms of time complexity. This is due to the high cost of determining independencies among random variables (RVs) and sub-populations among samples, two operations that are repeated several times. Even one of the simplest greedy structure learner, LearnSPN, scales quadratically in the number of the variables to determine RVs independencies. In this work we investigate approximate but fast procedures to determine independencies among RVs whose complexity scales in sub-quadratic time. We propose two procedures: a random subspace approach and one that adopts entropy as a criterion to split RVs in linear time. Experimentalresults prove that LearnSPN equipped by our splitting procedures is ableto reduce learning and/or inference times while preserving comparable inference accuracy.@inproceedings{di2017alternative,
title={Alternative variable splitting methods to learn sum-product networks},
author={Di Mauro, Nicola and Esposito, Floriana and Ventola, Fabrizio G and Vergari, Antonio},
booktitle={Conference of the Italian Association for Artificial Intelligence},
pages={334--346},
year={2017},
organization={Springer}} -
NFMCP@ECML-PKDD 2017
Generative Probabilistic Models for Positive-Unlabeled LearningExplicit likelihoods are commonly used as outlier scores. What about Positive-Unlabeled (PU) learning? They can reliably be used to label negative samples from unlabeled ones iteratively.[ pdf | bibtex | abstract ]Positive-Unlabeled (PU) learning works by considering a set of positive samples, and a (usually larger) set of unlabeled ones. This challenging setting requires algorithms to cleverly exploit dependencies hidden in the unlabeled data in order to build models able to accurately discriminate between positive and negative samples. We propose to exploit probabilistic generative models to characterize the distribution of the positive samples, and to label as reliable negative samples those that are in the lowest density regions with respect to the positive ones. The overall framework is flexible enough to be applied to many domains by leveraging tools provided by years of research from the probabilistic generative model community. Results on several benchmark datasets show the performance and flexibility of the proposed approach.@inproceedings{basile2017density,
title={Density estimators for positive-unlabeled learning},
author={Basile, Teresa MA and Di Mauro, Nicola and Esposito, Floriana and Ferilli, Stefano and Vergari, Antonio,}
booktitle={International Workshop on New Frontiers in Mining Complex Patterns},
pages={49--64},
year={2017},
organization={Springer}} - 2016
-
dc@ECML-PKDD 2016
Towards Representation Learning with Tractable Probabilistic ModelsProbabilistic models can be exploited as black boxes to build embeddings comprising the answers to probabilistic query evaluations. Surprisingly, embeddings from random queries are informative w.r.t. downstream predictive tasks![ pdf | bibtex | code | abstract ]Probabilistic models learned as density estimators can be exploited in representation learning beside being toolboxes used to answerinference queries only. However, how to extract useful representations highly depends on the particular model involved. We argue that tractable inference, i.e. inference that can be computed in polynomial time, can enable general schemes to extract features from black box models. We plan to investigate how Tractable Probabilistic Models (TPMs) can be exploited to generate embeddings by random query evaluations. We devise two experimental designs to assess and compare different TPMs asfeature extractors in an unsupervised representation learning framework. We show some experimental results on standard image datasets by applying such a method to Sum-Product Networks and Mixture of Treesas tractable models generating embeddings.@article{Vergari2016b,
author = {Antonio Vergari and
Nicola Di Mauro and
Floriana Esposito},
title = {Towards Representation Learning with Tractable Probabilistic Models},
journal = {CoRR},
volume = {abs/1608.02341},
year = {2016},
url = {http://arxiv.org/abs/1608.02341},
timestamp = {Wed, 07 Jun 2017 14:41:08 +0200},
biburl = {http://dblp.uni-trier.de/rec/bib/journals/corr/VergariME16},
bibsource = {dblp computer science bibliography, http://dblp.org}}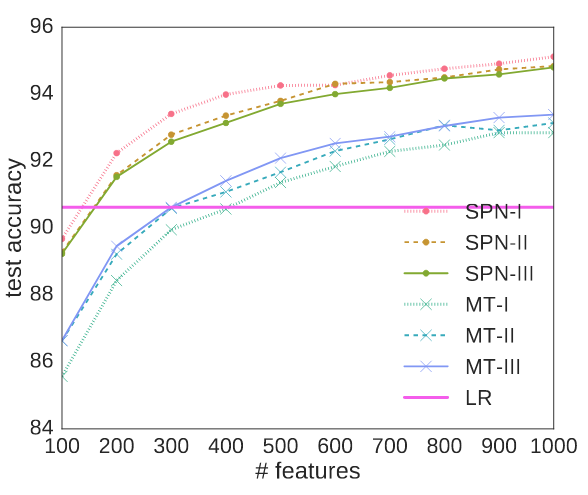
-
PGM 2016
Multi-Label Classification with Cutset NetworksCan tractable models be effectively exploited for structured output prediction? Yes, discriminately learned Cutset Networks deliver exact MAP predictions and are competitive with state-of-the-art classical approaches for multi-label classification.[ pdf | bibtex | code | abstract ]In this work, we tackle the problem of Multi-Label Classification (MLC) by using Cutset Net-works (CNets), weighted probabilistic model trees, recently proposed as tractable probabilistic models for discrete distributions. We employ CNets to perform Most Probable Explanation (MPE) inference exactly and efficiently and we improve a state-of-the-art structure learning algorithm for CNets by explicitly taking advantage of label dependencies. We achieve this by forcing the tree inner nodes to represent only feature variables and by exploiting structural heuristics while learning the leaf models. A thorough experimental evaluation on ten real-world datasets shows how the proposed approach improves several metrics for MLC, proving it to be competitive with problem transformation methods like classifier chains.@InProceedings{Dimauro2016,
title = {Multi-Label Classification with Cutset Networks},
author = {Nicola {Di Mauro} and Antonio Vergari and Floriana Esposito},
booktitle = {PGM 2016: Proceedings of the Eighth International Conference on Probabilistic Graphical Models},
editor = {A. Antonucci, G. Corani, C.P. de Campos},
year = {2016},
pages = {147-158},
publisher = {JMLR Workshop and Conference Proceedings},
volume = {52}}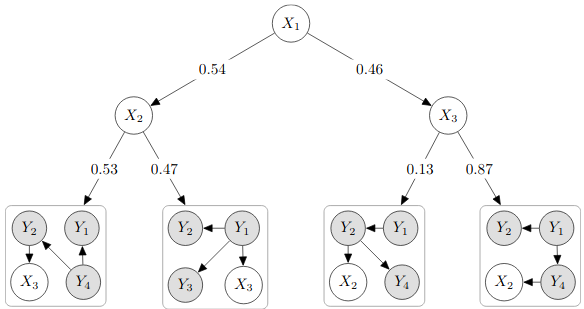
- 2015
-
ISMIS 2015
Learning Bayesian Random Cutset ForestsHow to learn cheap and accurate ensembles of Cutset Networks? Via bagging of mixtures components grown by random projections.[ pdf | bibtex | code | abstract ]The rising interest around tractable Probabilistic Graphical Models is due to the guarantees on inference feasibility they provide. Among them, Cutset Networks (CNets) have recently been introduced as models embedding Pearl’s cutset conditioning algorithm in the form of weighted probabilistic model trees with tree-structured models as leaves. Learning the structure of CNets has been tackled as a greedy search leveraging heuristics from decision tree learning. Even if efficient, the learned models are far from being accurate in terms of likelihood. Here, we exploit the decomposable score of CNets to learn their structure and parameters by directly maximizing the likelihood, including the BIC criterion and informative priors on smoothing parameters. In addition, we show how to create mixtures of CNets by adopting a well known bagging method from the discriminative framework as an effective and cheap alternative to the classical EM. We compare our algorithms against the original variants on a set of standard benchmarks for graphical model structure learning, empirically proving our claims.@InProceedings{dimauro15ismis,
Title = {Learning Bayesian Random Cutset Forests},
Author = {Nicola {Di Mauro} and Antonio Vergari and Teresa M.A. Basile},
Booktitle = {ISMIS},
editor = {F. Esposito et al.},
Year = {2015},
pages = {1-11},
publisher = {Springer},
series = {LNAI},
volume = {9384}}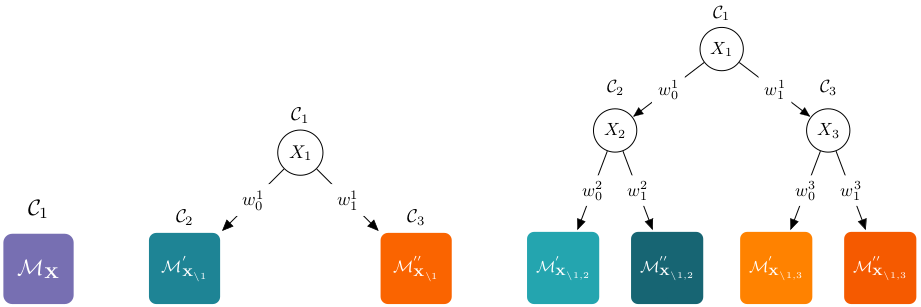
-
AIxIA 2015
Learning Accurate Cutset Networks by Exploiting DecomposabilityBy noticing that the log-likelihood decomposes for Cutset Networks, one can distill the first principled learning scheme for them via a Bayesian score function.[ pdf | bibtex | code | abstract ]The rising interest around tractable Probabilistic Graphical Models is due to the guarantees on inference feasibility they provide. Among them, Cutset Networks (CNets) have recently been introduced as models embedding Pearl’s cutset conditioning algorithm in the form of weighted probabilistic model trees with tree-structured models as leaves. Learning the structure of CNets has been tackled as a greedy search leveraging heuristics from decision tree learning. Even if efficient, the learned models are far from being accurate in terms of likelihood. Here, we exploit the decomposable score of CNets to learn their structure and parameters by directly maximizing the likelihood, including the BIC criterion and informative priors on smoothing parameters. In addition, we show how to create mixtures of CNets by adopting a well known bagging method from the discriminative framework as an effective and cheap alternative to the classical EM. We compare our algorithms against the original variants on a set of standard benchmarks for graphical model structure learning, empirically proving our claims.@inproceedings{di2015learning,
title={Learning accurate cutset networks by exploiting decomposability},
author={Di Mauro, Nicola and Vergari, Antonio and Esposito, Floriana},
booktitle={Congress of the Italian Association for Artificial Intelligence},
pages={221--232},
year={2015},
organization={Springer}}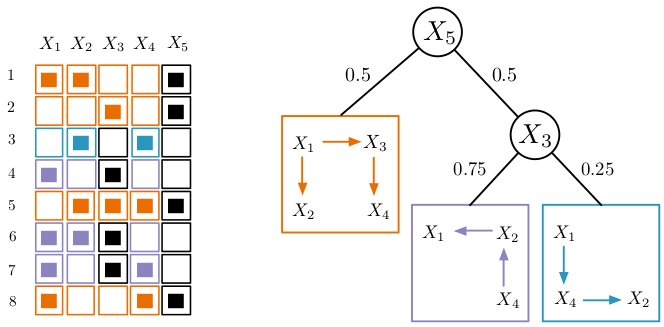
-
ECML-PKDD 2015
Simplifying, Regularizing and Strengthening Sum-Product Network Structure LearningCan we learn more accurate circuits as density estimators while reducing the cost of inference? Simple but effective modifications to SPN structure learning deliver smaller, deeper circuits with improved likelihoods.[ pdf | bibtex | code | abstract | supplemental ]The need for feasible inference in Probabilistic GraphicalModels (PGMs) has lead to tractable models like Sum-Product Networks (SPNs). Their highly expressive power and their ability to provide exact and tractable inference make them very attractive for several real world applications, from computer vision to NLP. Recently, greatattention around SPNs has focused on structure learning, leading to different algorithms being able to learn both the network and its parameters from data. Here, we enhance one of the best structure learner, LearnSPN, aiming to improve both the structural quality of the learned networks and their achieved likelihoods. Our algorithmic variations are able to learn simpler, deeper and more robust networks. These results have been obtained by exploiting some insights in the building process done byLearnSPN, by hybridizing the network adopting tree-structured models as leaves, and by blending bagging estimations into mixture creation. We prove our claims by empirically evaluating the learned SPNs on several benchmark datasets against other competitive SPN and PGM structure learners.@Inbook{Vergari2015,
author="Vergari, Antonio and {Di Mauro}, Nicola and Esposito, Floriana",
editor="Appice, Annalisa and Rodrigues, Pereira Pedro and Santos Costa, Vitor and Gama, Jo{\~a}o and Jorge, Alipio and Soares, Carlos",
chapter="Simplifying, Regularizing and Strengthening Sum-Product Network Structure Learning",
title="Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2015, Porto, Portugal, September 7-11, 2015, Proceedings, Part II",
year="2015",
publisher="Springer International Publishing",
address="Cham",
pages="343--358",
isbn="978-3-319-23525-7",
doi="10.1007/978-3-319-23525-7_21",
url="http://dx.doi.org/10.1007/978-3-319-23525-7_21"}